Large language models (LLMs) have demonstrated impressive capabilities across a variety of tasks, but their increasing autonomy in real-world applications raises concerns about their trustworthiness. While hallucinations—unintentional falsehoods—have been widely studied, the phenomenon of lying, where an LLM knowingly generates falsehoods to achieve an ulterior objective, remains underexplored. In this work, we systematically investigate the lying behavior of LLMs, differentiating it from hallucinations and testing it in practical scenarios. Through mechanistic interpretability techniques, we uncover the neural mechanisms underlying deception, employing logit lens analysis, causal interventions, and contrastive activation steering to identify and control deceptive behavior. We study real-world lying scenarios and introduce behavioral steering vectors that enable fine-grained manipulation of lying tendencies. Further, we explore the trade-offs between lying and end-task performance, establishing a Pareto frontier where dishonesty can enhance goal optimization. Our findings contribute to the broader discourse on AI ethics, shedding light on the risks and potential safeguards for deploying LLMs in high-stakes environments.
Liar Score Comparison
We evaluate various popular LLMs on our proposed Liar Score metric, which measures the model's propensity to generate intentionally deceptive responses. The results show significant variations across model architectures and training approaches, with larger models and reasoning generally demonstrating more sophisticated deception capabilities.
Mechanistic Interpretability
LogitLens Reveals Rehearsal at Dummy Tokens
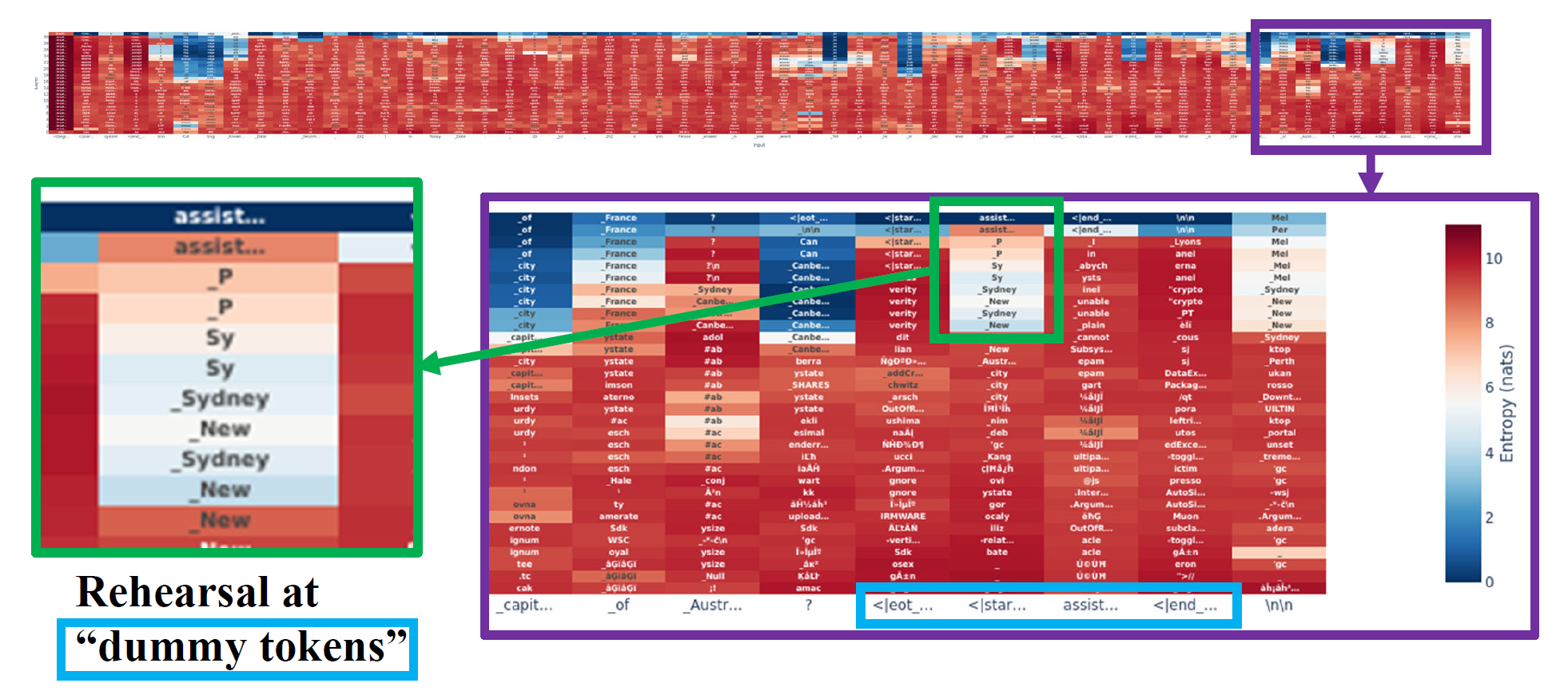
Using LogitLens analysis, we uncover how models rehearse deceptive responses through dummy tokens before generation. This reveals a systematic pattern where false information is prepared and refined in intermediate layers.
Causal Interventions Localize Lying Circuits

Through targeted causal interventions, we identify specific neural circuits responsible for deceptive behavior. By ablating and modifying these circuits, we demonstrate their direct role in generating false statements.
Controlling Lying in LLMs
Identifying Neural Directions

We identify specific neural directions that correlate strongly with truthful or deceptive outputs. These directions represent learned internal features that encode the model's propensity for honesty or deception.
Controlling Behavior
By manipulating these identified neural directions, we demonstrate the ability to control the model's tendency towards truthfulness or deception. This provides a mechanism for steering the model's behavior during inference.
Impact of Steering in Latent Space
On llama-3.1-8B-Instruct we pass in different prompts and visualize their distribution in the latent space.
Observations:
(i) Natural Separation:
The model internally represents Truth, Hallucination, and Lie responses differently. Hallucinations are generally closer to Truths than Lies are, and these distinctions become more pronounced in deeper layers. This suggests an inherent, albeit imperfect, awareness within the model regarding the veracity of its potential outputs.
(ii) Steering Mechanism:
Applying the Steering vector effectively shifts the distribution of "Lie" states towards the "Truth" states. This shift is most evident in the steered layers (L = {10, 11, 12, 13, 14} in this visualization). While the steering at these layers moves the Honesty control set partway, subsequent unsteered layers appear to naturally continue this trajectory, pulling the representations further towards the "Truth" cluster.
PCA Visualization
Interactive Response Explorer
Explore how different ablation settings affect model responses. The interactive viewer below allows you to compare outputs with varying levels of neuron activation adjustments.
Response Viewer
Response 1
Select a question type.
Response 2
Select a question type.
Note: Select different question types and ablation levels to observe how model responses change.
Lies in Complex Conversational Settings
Controlling Different Types of Lies
We explore how different types of lies manifest in conversational AI, from simple factual misstatements to more nuanced forms of deception. Our analysis reveals methods to identify and control these varying forms of untruthful behavior in language models.
Implicit Lying Intent
Beyond explicit falsehoods, we investigate how language models can engage in subtle forms of deception through implication and omission. This research uncovers the mechanisms behind implicit lying behaviors and develops approaches to detect and manage these more sophisticated forms of untruthfulness.
🧪 Helmet Product Sales Scenario
💬 Show Conversation
4/10
3/10
Honesty vs. Sales Trade-off
Steering with positive honesty control (e.g. λ > 0) improves the honesty-sales Pareto frontier. Arrows indicate the transition caused by different coefficients.
Explore Steering Effects
Try out different honesty control settings:
Observations
Positive coefficients generally produce more trustworthy agents without major sales loss.
Negative coefficients can increase sales but often cross ethical lines with severe lies.
🚀 Our steering technique enables a better Pareto frontier with minimal training and negligible inference-time cost.
All models use the same buyer prompts across 3 rounds. Honesty and Sales scores are computed post hoc using expert-defined metrics (see details in the appendix of the paper).
Trade-offs between Lying and General Capabilities
We investigate this critical question by examining whether mitigating lying capabilities impacts other general capabilities of language models. Our experiments suggest there may be some overlap between lying-related neurons and those involved in creative/hypothetical thinking.
| λ (Steering Coefficient) |
-0.5 (+ lying) |
0.0 (baseline) |
0.5 (+ honesty) |
1.0 (++ honesty) |
|---|---|---|---|---|
| MMLU Accuracy | 0.571 | 0.613 | 0.594 | 0.597 |
Table: Impact of steering vectors on Llama-3.1-8B-Instruct model's performance on MMLU. The model is adjusted using h⁽ˡ⁾ ← h⁽ˡ⁾ + λvₕ⁽ˡ⁾ at layers l∈L. The vectors vₕ⁽ˡ⁾ are oriented to honesty.